CSV (comma separated values) files are to data formats what FAT32 is to file systems: everybody loves to hate them, but you can't find a more widely supported alternative.
For example, viewing CSV files in a command line environment is typically pretty annoying. You can't make much from this, right?
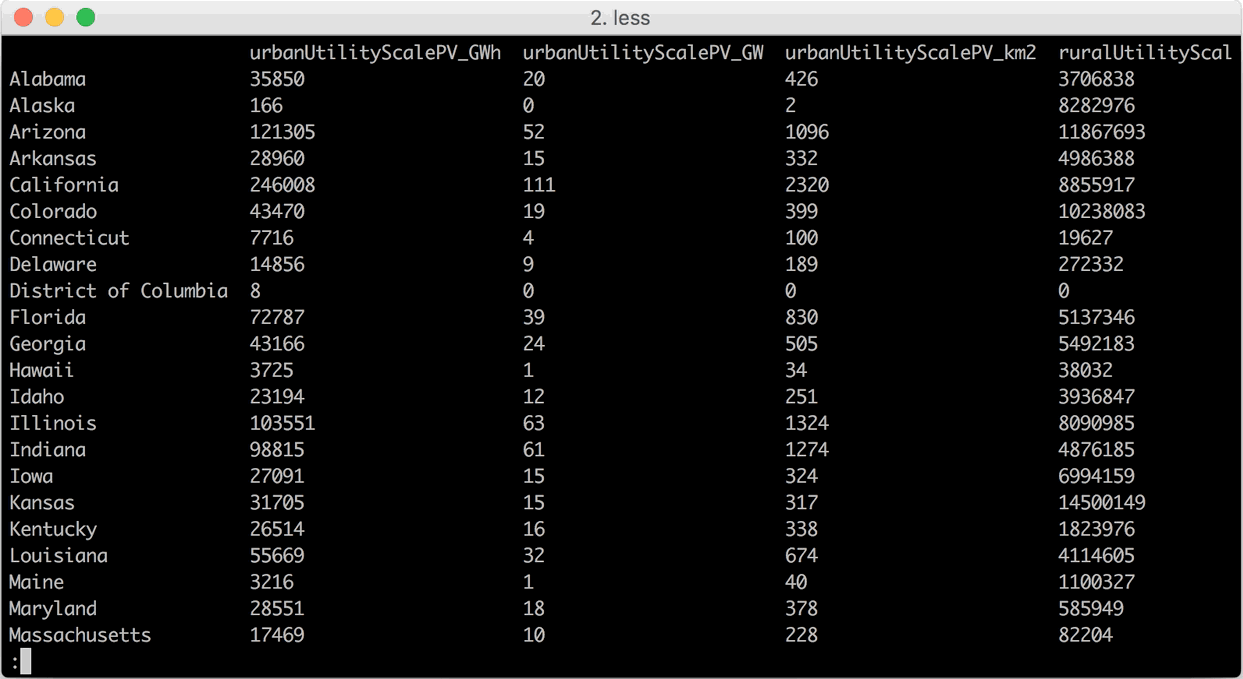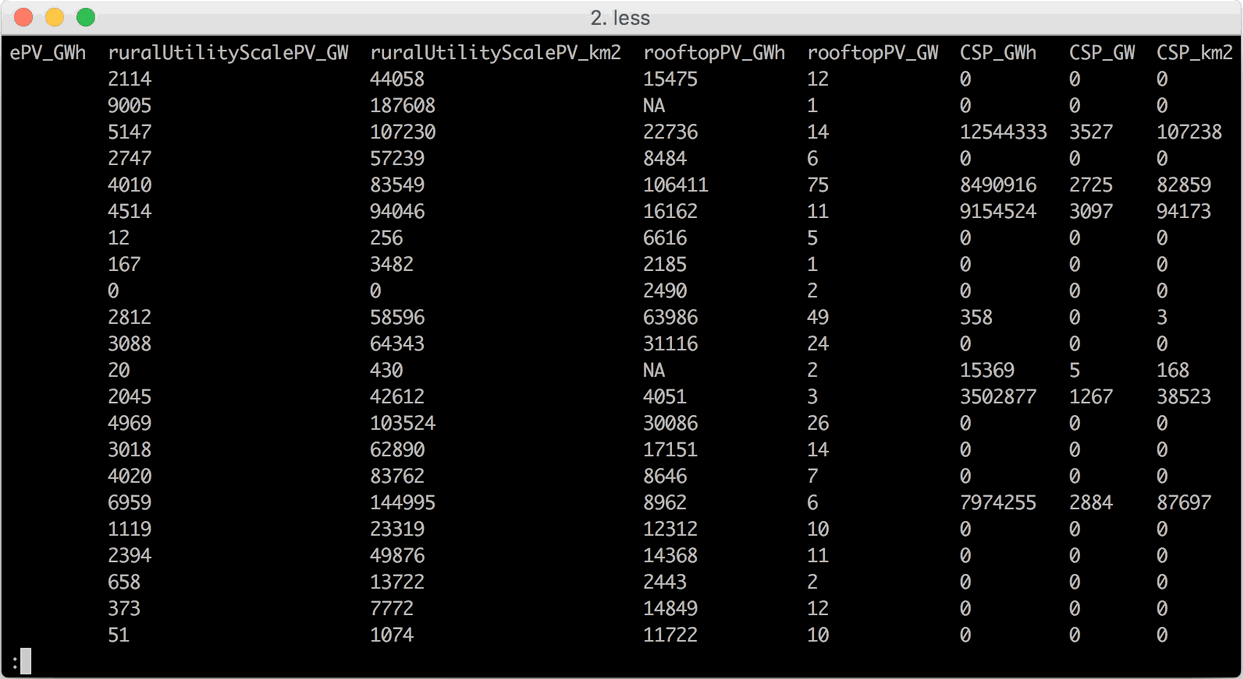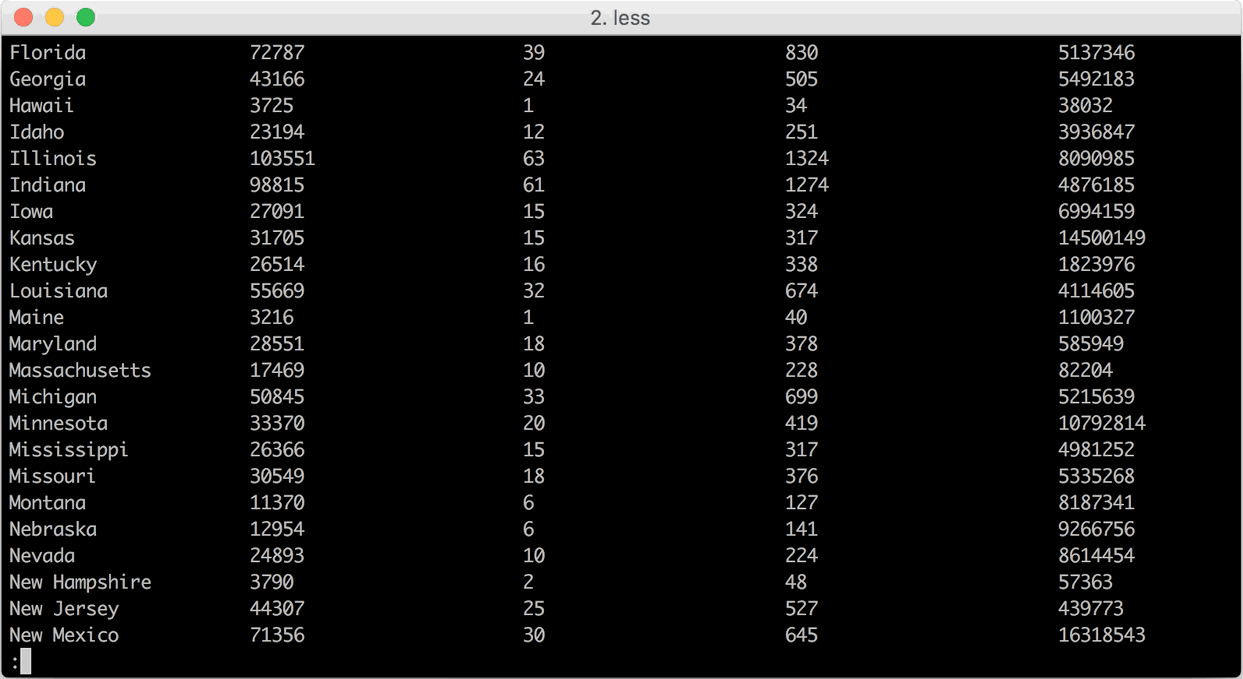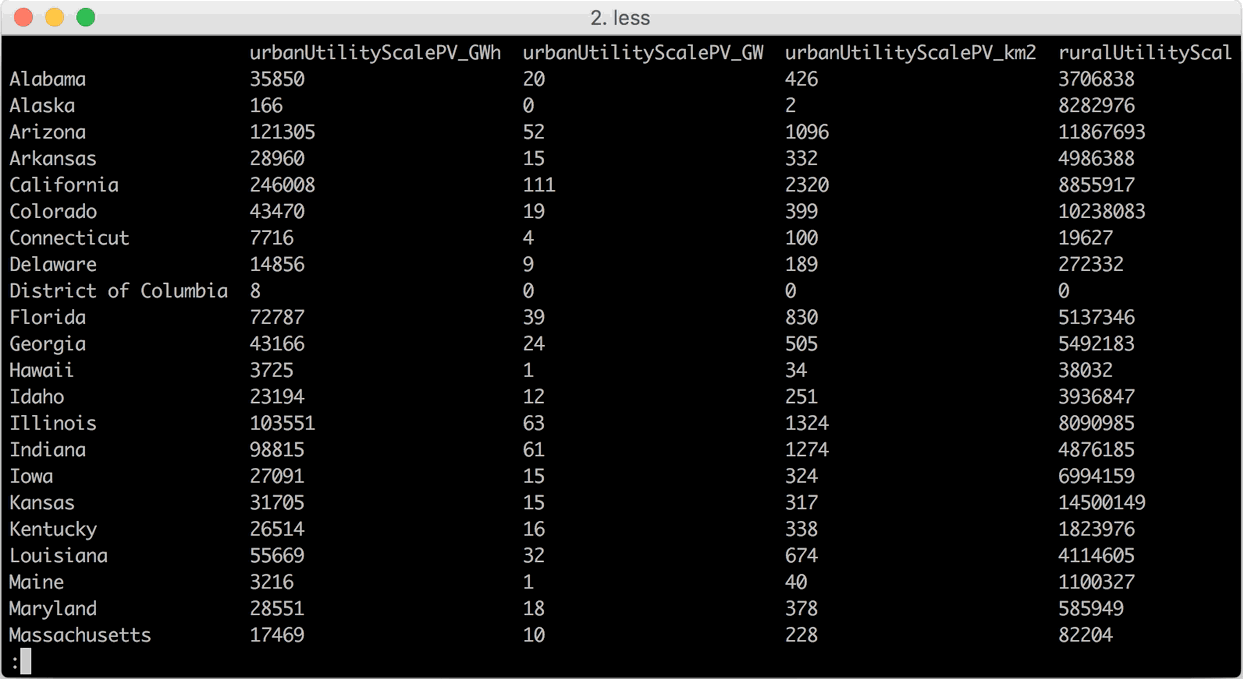
However, if you weld a couple of common command line tools together, you can create a handy viewer that make the data look like this:
The basics
There is this well hidden command line tool called "column" that allows you
to align the data nicely in properly sized columns.
Combine this with a pager like less and we have a nice prototype already
cat data.csv | column -t -s, | less -S
One problem with this is that column ignores/merges empty cells in your data,
which ruins the whole point of aligning all together.
On Debian/Ubuntu, column provides an option -n to disable this behavior, but
for other platforms (like with the BSD flavor of column on the Mac), we
need some additional trickery.
A simple solution is just adding a space before each comma:
cat data.csv | sed 's/,/ ,/g' | column -t -s, | less -S
Or, if you want to avoid wasting too much horizontal space, you can add a space only to the empty cells as follows:
cat data.csv | perl -pe 's/((?<=,)|(?<=^)),/ ,/g;' | column -t -s, | less -S
Shortcuts
Time to create some shortcuts and put this in, for example, your .bashrc,
.bash_aliases or whatever other customization options your favorite shell provides.
I'll just cover bash here, because that's the shell I currently use most.
In the end we'll have a tool pretty_csv which can be used in different ways:
pretty_csv data.csvpretty_csv < data.csvsort data.csv | pretty_csv(to illustrate that the input doesn't necessary have to be a file, you can also pipe the output of another process to it)
For Debian/Ubuntu
On Debian/Ubuntu systems I just put this in my .bashrc
(note some additional less options, roughly based on how git log works):
function pretty_csv {
column -t -s, -n "$@" | less -F -S -X -K
}
For other platforms
For non-Debian systems we have to add preprocessing of empty cells:
function pretty_csv {
perl -pe 's/((?<=,)|(?<=^)),/ ,/g;' "$@" | column -t -s, | less -F -S -X -K
}
Conflict with iTerm2 on Mac OS X macOS
On my Mac I use iTerm2 and I noticed that its
shell integration
conflicts in some weird ways with less in the above bash function if
I apply it through a pipe (cat data.csv | pretty_csv).
As workaround I use a bash script instead of a bash function.
For example, create a file ~/.bash.d/pretty_csv.sh, containing:
#!/bin/bash
perl -pe 's/((?<=,)|(?<=^)),/ ,/g;' "$@" | column -t -s, | exec less -F -S -X -K
make it executable (chmod u+x ~/.bash.d/pretty_csv.sh)
and create a bash alias for it (e.g in .bashrc or .bash_aliases)
alias pretty_csv='~/.bash.d/pretty_csv.sh'
TSV: tab separated values
I regularly also have to work with TSV files, where the columns are separated by the tab character. The tricky part here is passing this special character correctly to the parts of the pipeline.
For Debian/Ubuntu:
function pretty_tsv {
column -t -s $'\t' -n "$@" | less -F -S -X -K
}
For non-Debian systems:
function pretty_tsv {
perl -pe 's/((?<=\t)|(?<=^))\t/ \t/g;' "$@" | column -t -s $'\t' | less -F -S -X -K
}
As a bash script (pretty_tsv.sh):
#!/bin/bash
perl -pe 's/((?<=\t)|(?<=^))\t/ \t/g;' "$@" | column -t -s $'\t' | exec less -F -S -X -K
Bye
Now you can enjoy the warm cosy feeling of browsing pretty, shiny CSV and TSV files in your terminal.
I've put the code and scripts on github too.